

Joshua Yamdogo
25th March, 2021
Jira
Confluence
Bitbucket



How to use ScriptRunner to automate your code review best practices
We share how we built out some simple automations using ScriptRunner to simplify a team-defined process for code-review best practice. Plus, use our code snippets to build it for yourself!
I’m Josh, Software Engineer on the ScriptRunner for Confluence team here at Adaptavist. If you’re using Jira and Confluence for your development workflow, this post is for you.
After a little encouragement from the creator of ScriptRunner himself, Jamie Echlin, I’m going to share with you how we built out some simple automations (using ScriptRunner) to simplify a team-defined process for code-review best practice. Plus, I’ve included some free code snippets so you can build it for yourself today!
Here's an xkcd comic that basically lays out the situation...

What was the problem?
On the ScriptRunner for Confluence team, we have a peer code review system where each developer has an assigned person who reviews their pull requests. If you're not familiar with the pull request process, it's basically just a phase in the development cycle where new code is reviewed in order to provide feedback and suggest improvements.
At the beginning of each sprint, every developer is assigned a review "buddy", meaning that twice a month, you get someone new to review your code. It may sound cutesy or juvenile to assign a buddy, but it’s actually code review best practice and we've learned that, without this system, confusion and a lack of ownership can occur.
Before we adopted our rotating peer reviewer system, we’d sometimes get confusion around who should review each of our pull requests. Also, it wasn't always clear to the reviewer that they were supposed to provide feedback in a timely manner. So, that’s why we came up with a buddy system. How did we do it? We simply made a table on a Confluence page detailing who the buddy was for the current sprint.
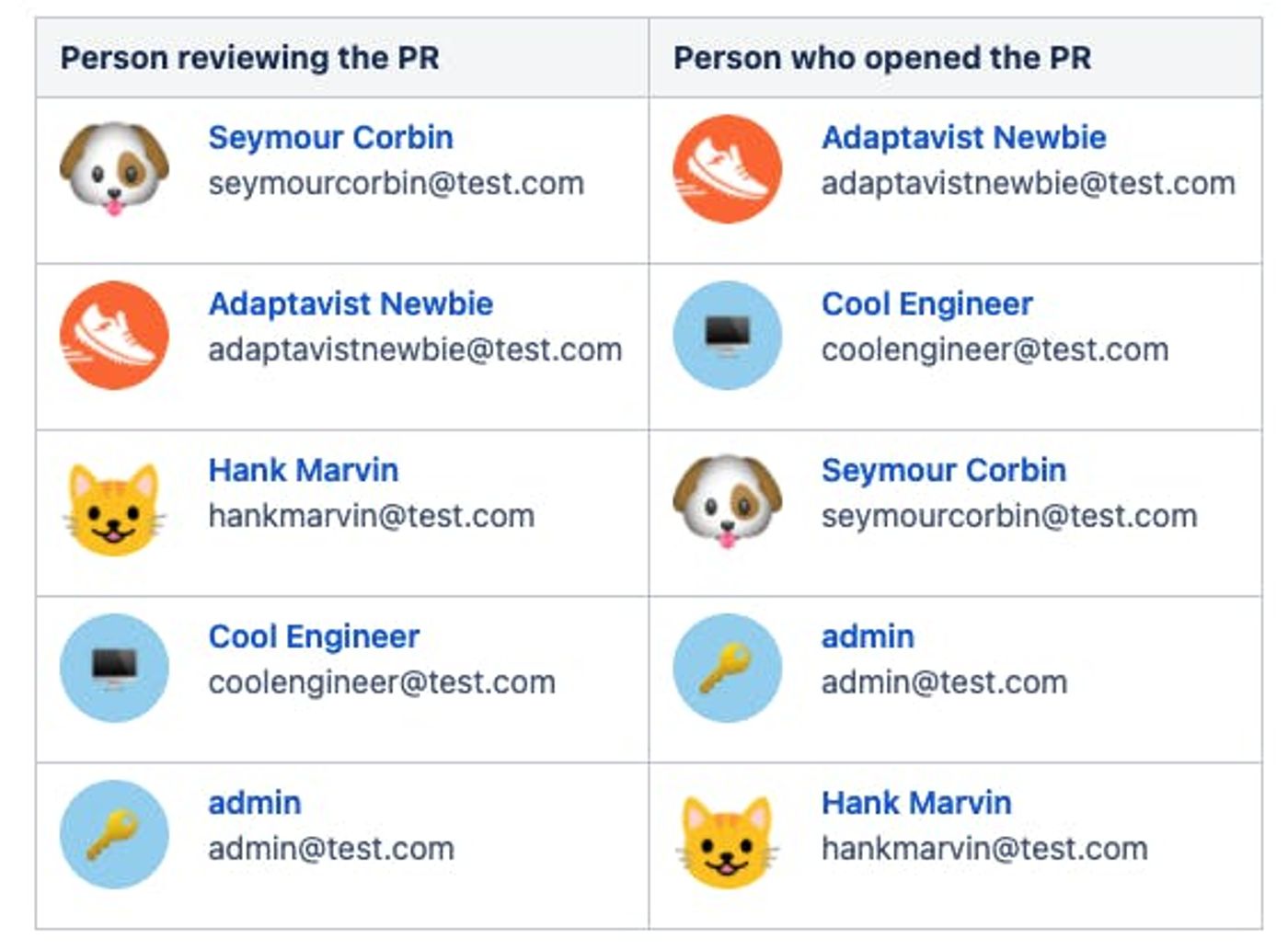
But, the problem with using a simple table on your Confluence page is that it needs to be manually edited every two weeks to ensure that each person gets a new buddy. You may be thinking: ‘Josh, that really doesn't sound hard...!’ And you would be right, but I don't want to have to manually edit a table and think about which name goes where. I studied Computer Science, not Table Editing Science.
What was the solution?
To remove this manual editing process, we set up some simple automations using ScriptRunner, to do the work for us — no manual intervention required at all. In a perfect world, we also wanted to receive a notification when a rotation took place, so we didn’t have to even check the page!
How we automated our peer code review system with ScriptRunner
Here's an overview of our technical solution:

Let's break down the four distinct parts of the workflow.
Part 1: A new sprint is started
As explained before, the rotation needs to occur at the beginning of every sprint. If you're lucky enough not to be a Product Manager, you may have never actually started a sprint yourself. That being said, whenever a sprint is started for a project in Jira, an event gets fired off within the fiery depths of Jira's internal code. That event is aptly named ‘SprintStartedEvent’. If only we could have some way to listen for that event, we could start the whole automation off...
Part 2: Script Listener
Lucky for us, a core feature of ScriptRunner is the ability to listen for specific events in specific projects. So, all we had to do was set up a Custom Listener on our Jira instance that was configured to listen for ‘SprintStartedEvent’.
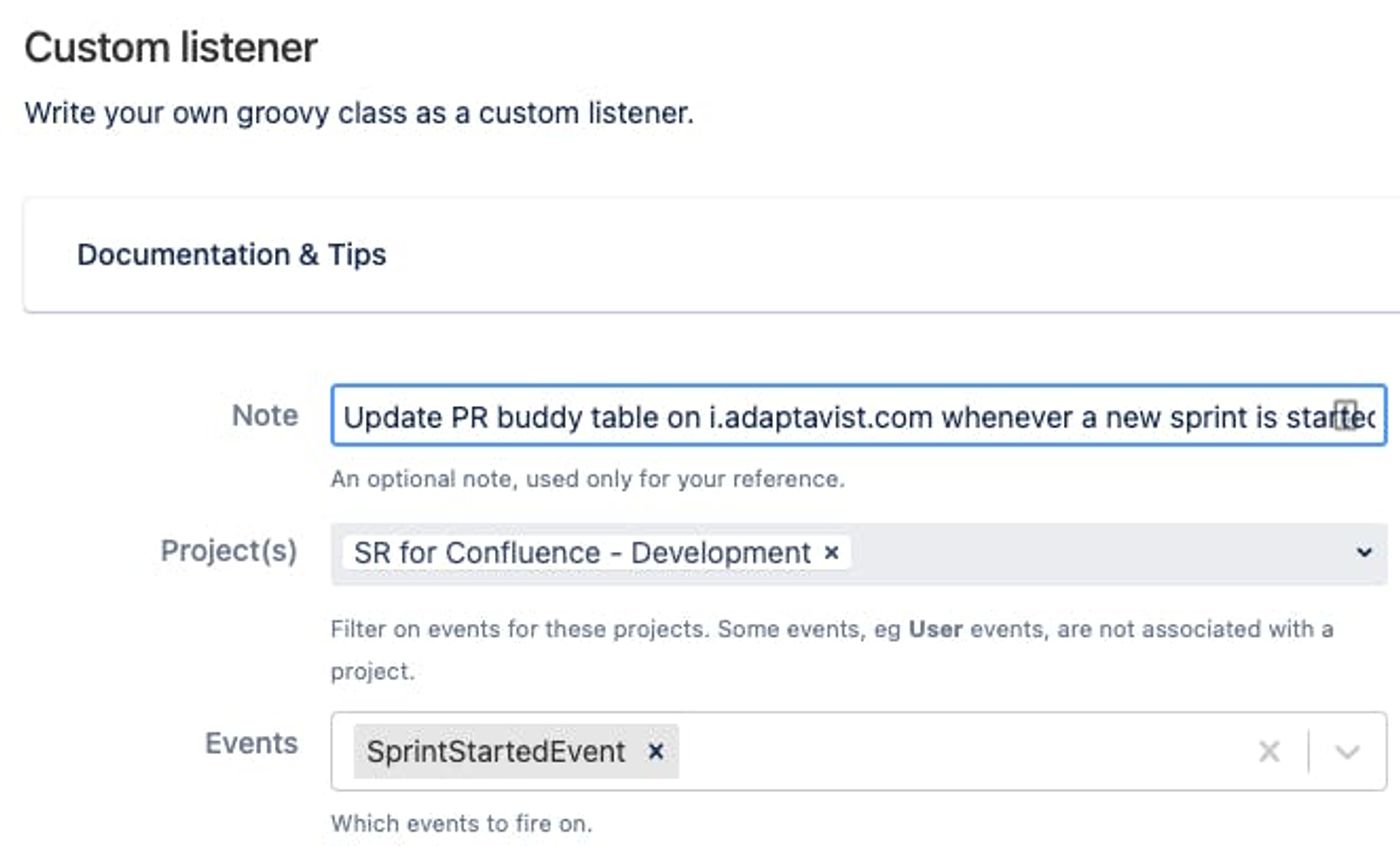
Now that we could catch SprintStartedEvent, next we needed a way to communicate with our Confluence instance in order to actually change the table on the page we want to update automatically. We achieved this communication by making a simple request to our Confluence instance within a script. Because Adaptavist's Confluence and Jira instances are linked using ApplicationLinks, there’s no need to put any credentials within the script itself. (For more detail on this, see the ScriptRunner documentation.)
Here's the script we used to contact Confluence:
1import com.atlassian.applinks.api.ApplicationLink
2import com.atlassian.applinks.api.ApplicationLinkResponseHandler
3import com.atlassian.applinks.api.ApplicationLinkService
4import com.atlassian.applinks.api.application.confluence.ConfluenceApplicationType
5import com.atlassian.greenhopper.service.sprint.Sprint
6import com.atlassian.jira.component.ComponentAccessor
7import com.atlassian.sal.api.net.Response
8import com.atlassian.sal.api.net.ResponseException
9import com.onresolve.scriptrunner.canned.jira.utils.plugins.RapidBoardUtils
10import groovy.json.JsonSlurper
11
12import static com.atlassian.sal.api.net.Request.MethodType.GET
13
14def CONFLUENCE_URL = 'https://confluence.instance.com/' // Change this to your Confluence instance URL
15def CONFLUENCE_REST_PATH = 'path/to/your/rest-endpoint' // Change this to the path of your endpoint
16
17def sprint = event.sprint as Sprint
18def rapidBoardUtils = new RapidBoardUtils()
19def teamBoardId = rapidBoardUtils.getBoardId("SR4C Squad", ComponentAccessor.jiraAuthenticationContext.loggedInUser)
20
21if (!(sprint.rapidViewId == teamBoardId)) {
22 return
23}
24
25def appLinkService = ComponentAccessor.getComponent(ApplicationLinkService)
26
27def appLink = appLinkService.getApplicationLinks(ConfluenceApplicationType).find { ApplicationLink link -> link.displayUrl.toString().contains(CONFLUENCE_URL) }
28def applicationLinkRequestFactory = appLink.createAuthenticatedRequestFactory()
29
30def request = applicationLinkRequestFactory.createRequest(GET, "${CONFLUENCE_URL}${CONFLUENCE_REST_PATH}")
31
32def handler = new ApplicationLinkResponseHandler<Map>() {
33 @Override
34 Map credentialsRequired(Response response) throws ResponseException {
35 return null
36 }
37
38 @Override
39 Map handle(Response response) throws ResponseException {
40 assert response.statusCode == 200
41 new JsonSlurper().parseText(response.getResponseBodyAsString()) as Map
42 }
43}
44
45try {
46 request.execute(handler)
47 log.debug('SRCONF buddy table updated')
48}
49catch (Exception e) {
50 log.error("Failed to update SRCONF buddy table", e)
51}Part 3: The REST Endpoint on Confluence
Once our listener sees a SprintStartedEvent in Jira, it sends a request over to Confluence via a custom Script Endpoint. This endpoint actually contains the script that does the automatic editing of the table. Basically, all our script does is move down each person in the left-hand column of the table on our Confluence page. If the person on the left-hand column equals the person on the right-hand column, we shift again. (We don't want people reviewing their own code, what is this; 2015?!)
To achieve this, my colleague Aidan Derossett came up with a simple script:
1import com.atlassian.confluence.pages.PageManager
2import com.atlassian.sal.api.component.ComponentLocator
3import com.onresolve.scriptrunner.runner.rest.common.CustomEndpointDelegate
4import com.onresolve.scriptrunner.slack.SlackUtil
5import groovy.json.JsonBuilder
6import groovy.transform.BaseScript
7import org.jsoup.Jsoup
8import org.jsoup.nodes.Element
9
10import javax.ws.rs.core.MultivaluedMap
11import javax.ws.rs.core.Response
12
13@BaseScript CustomEndpointDelegate delegate
14updateBuddyTable(httpMethod: "GET", groups: ["adaptavist"]) { MultivaluedMap queryParams, String body ->
15 def pageManager = ComponentLocator.getComponent(PageManager)
16
17 def CONFLUENCE_PAGE_LINK = 'https://confluence.instance.com/path-to-your-page' // Change this to your Confluence instance page URL
18 def BUDDY_PAGE_NAME = 'ScriptRunner for Confluence Pull Request Process'
19 def USER_ATTRIBUTE_KEY = 'ri:userkey'
20
21 def page = pageManager.getPage('SR', BUDDY_PAGE_NAME)
22 def parsedBody = Jsoup.parse(page.bodyContent.body)
23 def tableCells = parsedBody.select('td')
24
25 List<Element> rightColumnCells = []
26 List<Element> leftColumnCells = []
27
28 tableCells.eachWithIndex { item, index ->
29 if (index % 2 == 0) {
30 leftColumnCells.add(item)
31 } else {
32 rightColumnCells.add(item)
33 }
34 }
35
36 def leftColumnUserKeys = leftColumnCells.collect {
37 it.getElementsByAttribute(USER_ATTRIBUTE_KEY)*.attr(USER_ATTRIBUTE_KEY)
38 }.flatten() as List<String>
39
40 def rightColumnUserKeys = rightColumnCells.collect {
41 it.getElementsByAttribute(USER_ATTRIBUTE_KEY)*.attr(USER_ATTRIBUTE_KEY)
42 }.flatten() as List<String>
43
44 rightColumnUserKeys.remove(rightColumnUserKeys.size() - 1)
45 Collections.rotate(leftColumnUserKeys, 1)
46
47 if (leftColumnUserKeys == rightColumnUserKeys) {
48 Collections.rotate(leftColumnUserKeys, 1)
49 }
50
51 leftColumnUserKeys.eachWithIndex { newUserKey, index ->
52 leftColumnCells[index].getElementsByAttribute(USER_ATTRIBUTE_KEY).first().attr(USER_ATTRIBUTE_KEY, newUserKey)
53 }
54
55 pageManager.saveNewVersion(page) { it.setBodyAsString(parsedBody.toString()) }
56
57 SlackUtil.message(
58 "sr4cbot",
59 "sr4c-squad",
60 ":cooldog: NEW SPRINT TIME :cooldog:\n <$CONFLUENCE_PAGE_LINK|The pull request buddy table has been updated!>"
61 )
62
63 return Response.ok(new JsonBuilder("$BUDDY_PAGE_NAME has been rotated.").toString()).build()
64}Part 4: Table updated and notifying the team
So now all of this is awesome and automated: when the above script within the REST endpoint is called, it will automatically update the table and give everyone a new buddy. Job done, right?
Wrong.
Remember I said we wanted to let everybody know? Communication is a huge part of DevOps best practice and we have a new nifty Jira-to-Slack ScriptRunner integration to use.
At the end of the script, there's some code to automatically post in our team Slack channel whenever our table is updated. Here's an example of the message that our new ScriptRunner4C bot posts in the chat:
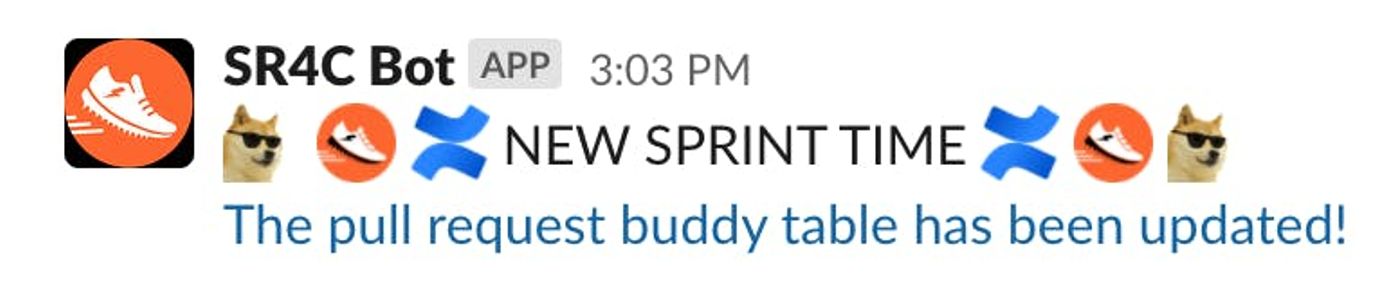
You can see our message has the cooldoge emoji. This is completely required if you want to be cool. Speaking of cool, it was another of my awesome colleagues, Jonathan Scalise, who kindly helped me set up my Slack bot. The guy is a wizard.
Part 5: Next steps
We could probably eliminate the table all together and just programmatically set reviewers for each person within Bitbucket. This could be accomplished with ScriptRunner for Bitbucket, but our table provides a nice visual reference and it works for us... so good enough for now.
Conclusion
While this may not save our team too much time in the grand scheme of things, it’s a great example to show automations don't have to be incredibly complex to provide immediate value.
For me, this was a great opportunity as a ScriptRunner developer to use our own product to solve a headache. It was an awesome chance to get an overview of our products and how they can connect to create efficiency.
If you create products, digital or physical, I'm sure you know the following to be true; it's one thing to develop something and it's an entirely different thing to actually use it. It honestly gives you a totally different perspective.
This project has also been a great chance to work with some awesome colleagues on a small project. Sometimes, it's about the journey and not the destination.
Looking for some other quick wins when it comes to ScriptRunner customisations, automations and integrations? Check out the script library where we’ve got bundles of free scripts ready for you to make your own.