

GUEST CONTRIBUTOR: Nishaat Rajabali
GUEST CONTRIBUTOR: Tomasz Bryla
4th October, 2022
Bitbucket


Getting Bitbucket control policies right at GAIN Capital
How GAIN Capital’s Productivity Tools Team (responsible for CI/CD) helped their developers to follow and understand best practices for positive outcome in development and delivery.
Developers don’t like anything they perceive as taking time away from actual coding, and prefer a barrier-free software development cycle. But, power is nothing without control, especially when developers are working through the process of moving from code to product delivery. That means, in order for a company to function, compliance and uniformity must be respected and enforced across the board. The DevOps/IT/Systems Manager is usually in charge of making sure this happens without missing any vital approval steps or slowing down operations.
In this post, we will detail how our Productivity Tools Team (responsible for CI/CD and Atlassian toolchain) helped GAIN Capital’s developers to follow and understand best practices for positive outcomes in product development and delivery. We hope this workable example will help others to discover the hassle-free process of automating and controlling their DevOps workflow and stop all the head-scratching.
Why is best practice compliance needed?
Like many other companies that grew through a series of acquisitions, we also had to start finding automated ways of overseeing the output of multiple development teams that were operating with different toolchains, set-ups and rules.
We started the consolidation work with tooling. For version control, we chose Bitbucket - it integrates seamlessly with Jira, and is much easier to set up and use than Team Foundation Server, now called Azure DevOps Server. However, everybody working on the same tools does not guarantee that they will be working or collaborating in the same way.
We found that not all the teams were following DevOps best practices, and each one of our teams was following their own rules. This could cause tracing and reporting problems, which for a heavily regulated financial company like ours can turn into an audit nightmare. We absolutely had to correct problems such as:
- No commit messages:
Users committing with very short or no commit messages are counterproductive, especially because Git history is merged as is from feature to trunk branch. - Commits not being associated with the Jira ticket ID:
Users were frequently forgetting to add the Jira ticket ID on the commit, which made it very difficult for reviewers to trace work. - Pushing binaries to Git:
Binaries increase repo size, which increases disk space consumption, and in turn increases git clone time both locally and in other systems such as on our CI/CD server. And once they make it to Git, destroying files and associated history is not easy.
It was clear to us that in order to enforce standards and smooth operations, we needed to add some ‘speed bumps’ on Bitbucket.
Implementing controls in Bitbucket
We set out to create and implement a series of control policies at the global level in Bitbucket.

In a nutshell, any push that didn’t comply with a control policy had to be automatically rejected. To achieve this inside Bitbucket, we created a series of ScriptRunner custom pre-hooks that trigger automatically upon ‘git push’.
To avoid bottlenecks while developers were getting used to the new rules, for the first few weeks the pre-hooks only returned warning messages instead of rejecting the push outright.
After that, we set up the pre-hooks to reject a push that didn’t comply with the rules. However, this setup allowed for some exceptions. For example, to permit break fixes, the pre-hook for commit message control accepts a push with [EMERGENCY] in the commit message.
Setting this up was easy. We have been using ScriptRunner for Jira for a long time, so Groovy scripting is natural to our team. You can see a couple of the scripts we used (written by Nishaat and Tomasz) here and here.
The set-up was easy, but getting our users to understand why these controls were necessary was more complicated. To achieve this, we relied on a solid documentation.
Having proper documentation is the easiest way to share knowledge among developers and to ensure managers don’t need to explain things over and over every time somebody new joins the company. In our case, every single Bitbucket control policy is scrupulously explained in our Confluence Wiki, and follows this model:
Policy name
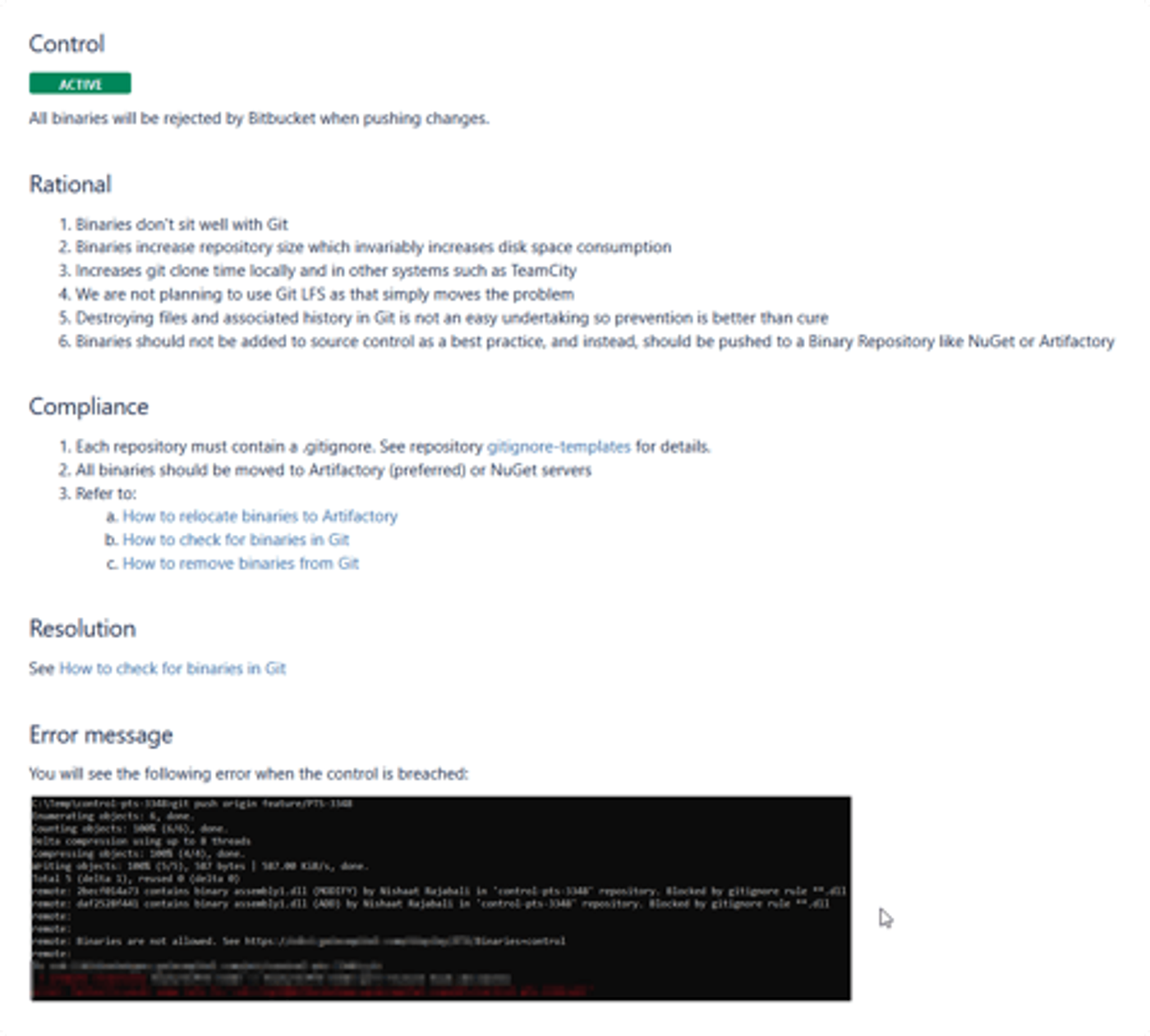
Control: What is the rule?
Rationale: Why do we need this rule?
Examples: What does it look like when the rule is respected?
Compliance: What steps to take to comply with this rule?
Resolution: What to do to resolve a conflict with this policy?
Error message: What is the exact error message you will get on Git if the conflict is not resolved?
When a control policy is breached in Bitbucket, the custom pre-hook rejects the push and returns a short ‘error message’ with a link to the detailed documentation on our wiki. This way, it’s easy for the developer to understand the reasons for the rejection and to know what they need to do in order to correct the situation.
From globally-enforced, to user-demanded
Not everyone openly embraces change, so as you can imagine, there was some initial resistance from our users when we announced these controls. Mostly, they perceived them as blockers that would slow down their ability to ship code fast. But, thanks to detailed documentation and our two step-approach to implementation (warning messages for the first weeks, instead of outright rejection) it did not take long for everybody to see the logic and relevance of best practice enforcement.
Even better, once the process was in full swing, they also started appreciating the benefits. We now have traceability and context for each commit, and communication among developers on code has improved tenfold.
Further proving adoption success, individual teams are now requesting more granular controls on their team repos and projects. Today, they often write their own scripts for custom hooks in ScriptRunner, which we then review, approve, and implement on their projects or repos. If their scripts turn out to be useful across all teams, we implement the new controls at global level. For example, one team wrote a local hook that searches through the checked-out branch name and extracts the Jira ID, and when it finds it, it then adds the [JIRA-ID] in the commit message. The local hook is automatically copied using git templates from a shared Bitbucket repository that the users clone. This reduces errors and the need to look for the Jira ID when working with multiple branches. We have plans to check Jira ID status in the future and only allow ‘In progress’ tickets.
--
ScriptRunner thanks GAIN Capital Productivity Tools Team Manager Nishaat Rajabali and Atlassian Specialist Tomasz Bryla for taking the time to share their experience in this post.